As companies aim to scale up their operation, they often discover that the vast majority of their processes should be automated by a data engineer. Yet, despite its undeniable advantages, according to Gartner, just 55% of businesses are convinced as to its value. This is ironic, considering that process automation has been shown to account for significant gains, both financially and in terms of efficiency.
According to research conducted by SnapLogic, organisations are losing $140 billion each year in wasted time and resources, duplication of effort, and missed opportunities as a result of disconnected data. Meanwhile, highly automated companies are six times more likely to see revenue growth of upwards of 15%. The statistics are compelling, so it’s remarkable uptake isn’t sky rocketing.

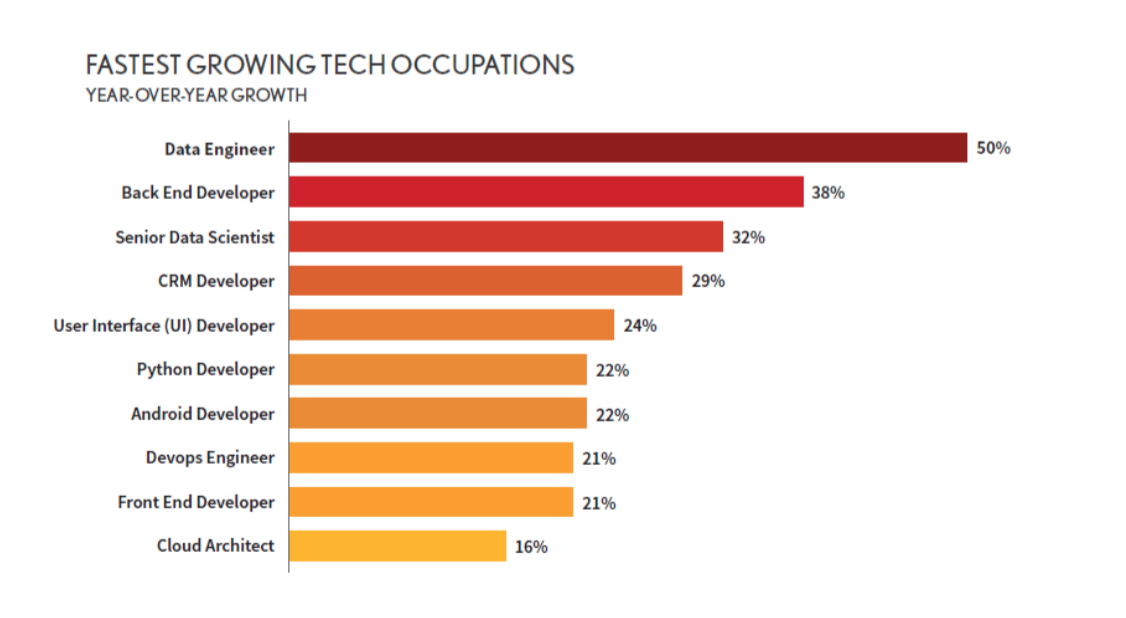
Therefore, companies that pursue automation are undoubtedly in a position to get ahead of the skeptics. However, the first tremors of this cultural shift are beginning to occur throughout the world; as a result, data engineers are increasingly in demand: name the industry and ‘data engineer’ is the fastest growing title on the job market.
With robust data engineering, companies can not only accelerate the delivery of services to clients, but also enhance quality. By improving efficiency, businesses can gain flexibility and scalability, which in turn, facilitates insights. This enhancement of business operations passes benefits back to the customer, as products and services become more innovative and agile. Equally, the company enjoys greater productivity and savings. It’s a nurturing feedback loop.
Table of Contents
What does a data engineer do anyway?
Although data engineer is a comparatively new title, the marked growth in demand is something to pay attention to. As reported at 2020 Dice Tech Job Report, data engineer is the fastest growing job in the USA and stands out by a significant margin. But aside from growth in demand, what does a data engineer do that is so important? Why are their skills so sought-after and useful to companies?
The range of tasks a data engineer performs fits roughly into three different profiles, which eventually merge into one over time. In most cases, this depends mostly, but not entirely, on the size of the organisation. Thus, we find three types of data engineers in any given organisation: in a small team or company, they’ll have a general role. In a mid-size organisation they’ll be pipeline-centric, while in large organisations, they’ll be database-centric.
Let’s break this down; in a small organisation, a data engineer will wear various different hats and manage the data management and analysis end-to-end. Generally speaking, they’ll be brought in to build process automation from scratch. They’ll collect, manage and analyse data, find patterns, and use programming languages and tools to replicate these occurrences.
In contrast, in a mid-size operation, the bulk of data collection will already be in process. These data will be stored in various settings, including data lakes, warehouse, and databases. The pipelines to process this data either need to be put in place, improved or refined. Namely, these will involve following one of two paradigms: ETL (Extract, Transform, Load) or ELT(Extract, Load, Transform).
These processes take a considerable percentage of the workload off data engineers, enabling them to focus on the data analysis process. Moreover, as automation may cause growth to gather speed across the organisation, a seamless acquisition and integration of data is critical. This is especially the case as data emanates from a myriad of other sources, some of which may be external. Subsequently, coordination between these data analysis tools is a must to move from a mid-scale data ecosystem to a large-scale one.
In large companies – and as scale becomes an element in and on itself – managing and ensuring the flow of data becomes crucial. Building databases and preparing data for predictive and prescriptive modelling is essential, while managing and structuring large datasets and designing methods of analysing data is vital to facilitating effective process automation. Data engineers must build a reliable data analysis process that maintains a high standard of security and full regulatory compliance.
In summary, a data engineer will perform a multi-faceted and complex role no matter the size of the organisation. The emphasis in their skillset will admittedly vary depending on the scale of the company, however, they should be versatile. So, in brief a certified data engineer should be able to deliver the following competencies:
- Build/maintain data structures and databases.
- Design data processing systems.
- Analyse data and enable machine learning.
- Design for reliability.
- Visualize data
- Advocate for policy.
- Model business processes for the analysis of data.
- Design for security and regulatory compliance.
Data engineer use case in the green energy sector
To demonstrate how an organisation can benefit from a data engineer’s work, we’ll guide you through a use case from a certified data engineer in Outvise’s portfolio. This expert’s services were solicited by a mid-size organisation in the green energy sector. Via a walk through of this use case, you can begin to see what lies in the realm of the possible when working with data in a specific context. From here, we can outline a more nuanced description of data engineering technologies in the cloud and on-site, no matter the size of the organisation.
Up Energy is a medium size company based in the UK that offers commercial energy assessment across the south of the country. This includes thermal modelling, energy performance certificates, SAP calculations, display energy certificates and more. They brought in a data engineer to identify which processes, operations, and business actions could be automated and how best to do that given the various context and scenarios.
At Up Energy, their need to automate a great deal of processes was clear from the outset. Of the many areas in which data engineering was necessary, the expert decided to focus on delivering on one particular target, namely, enhancing their thermal modelling analysis and overheating assessments.
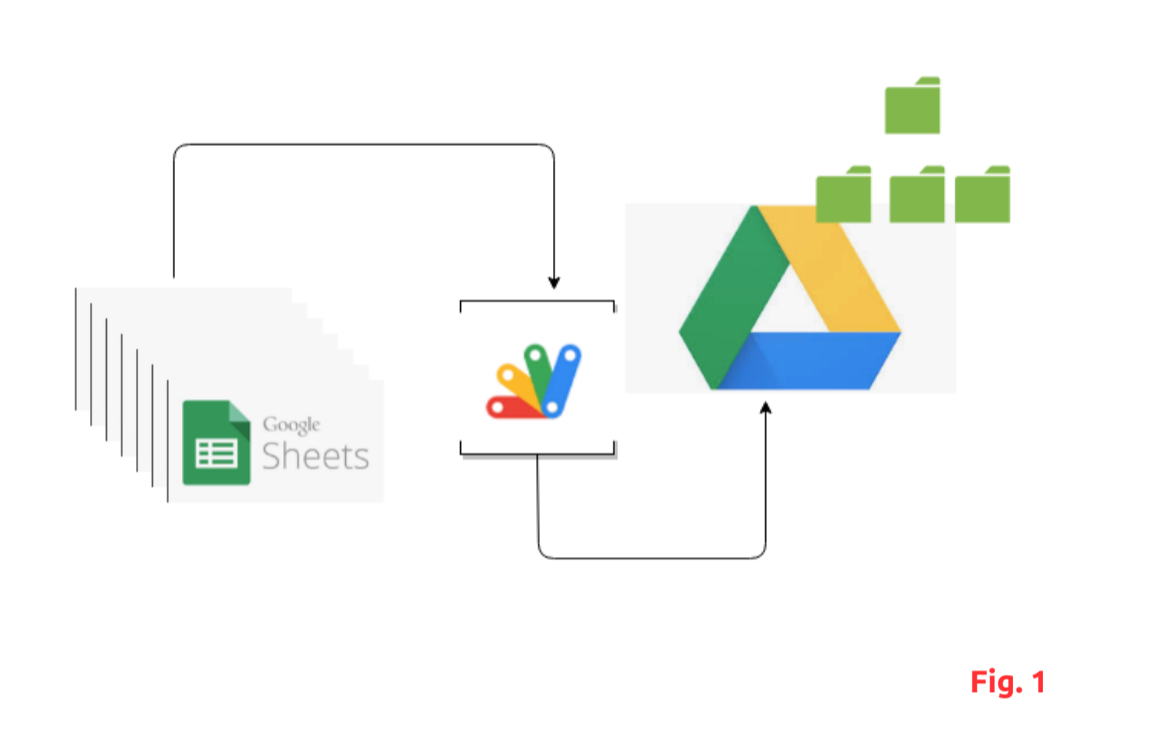
Candidates for ‘digitalization’ within this niche were business operations and analytics. On one hand, there was part of business operations that desperately required automation. In the past Up Energy’s clients would send project documentation via email. This, naturally, was disorganised and inefficient. Instead, the data engineer designed a system that migrated their communications to Google Suite, Google Sheets and Google Apps Script.
This automated the entire project documentation upload process, which was eventually delivered as a web app powered by Google Apps Script. This program is written in modern Javascript, where clients are prompted to upload a series of documents via Google Sheets. Custom functions are then executed, carrying a load of the data dynamically into Up Energy’s master Google Drive.
On the analytics front, Up Energy relied heavily on IESVE software, an in-depth suite of integrated analysis tools which, by the time the collaboration began, lacked a considerable number of features. As illustrated in Figure 2, after clients upload the corresponding project documents, Up Energy’s architects design and run 3D Dynamic Simulation Modeling, generating results and project data which is then made available via an API.
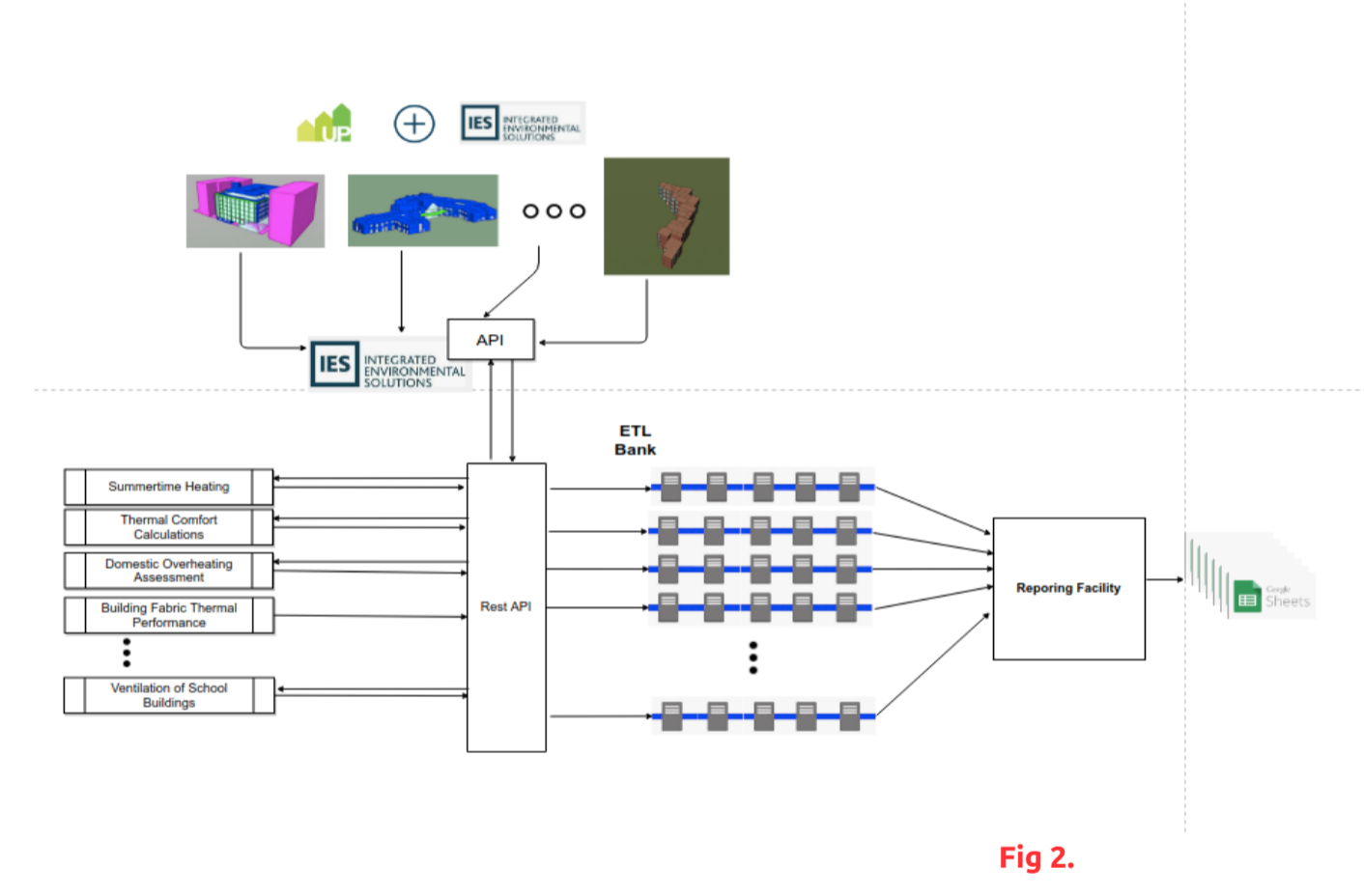
However feature-rich this data can be for certain use cases, Up Energy still lacked critical granularity. Thus, they solicited the data engineer to add more dimensions and features. Tackling each new feature separately allowed the engineer to familiarise himself in depth with IESVE’s API and account for all the caveats, particularities, possible shortcomings of such an application and accommodate the relevant resources accordingly.
Upon completion, the project team sought to further the expansion of the data analysis. Namely, they came up with new attributes, which were then turned into new features. The calculations associated with these new features and their underlying logic were then transferred to a set of ETL pipelines, assuming all possible combinations of transformation logic into a bank. In turn, each of the pipelines is triggered according to a set of rules specified hand-in-hand with architects. As seen in Figure 2, fetching data from IESVE API, the computed data points and config parameters for each type of thermal modelling subsequently ensured a successful trigger of ETL logic.
Last, but not least, further down the pipeline on the right side of the diagram beyond the ETL bank, the data engineer set up a bespoke reporting facility. This tool is in charge of formatting data to suit specific design aesthetics, in accordance to various layouts proposed by Up Energy.
For the duration of the project – approximately a month and a half – the power that data engineering and automation brings to clients became abundantly clear. These tools eased up work and cut timelines in both operations and analytics. Furthermore, when accurately assessed, a surplus of new and exciting opportunities arose, not only for full-fledged growth, but for a more nuanced view and understanding of what businesses can and can’t do with data.
The advantages of hiring external data engineer expertise
Certainly, data engineers have substantial value; but if this position is so valuable, why hire a freelancer over taking on an internal expert? There are three key aspects to this question: automation, efficiency, and rolling out proven use cases. Here, we’ll briefly outline the advantages of hiring external expertise according to these three key points.
First up, automation. Data engineering is, by nature, about automation. Thus, when the system is in place it should be just that – autonomous. Thus, an expert is brought in to build and design the system and once this task is complete, their work at the company is done. Of course, this is with the exception of incremental upgrades and adjustments according to shifting technologies and market dynamics.
This is linked to the second, efficiency. This model of hiring in expertise when the company needs it saves the company money, ensuring the personnel budget is spent at relevant, strategic junctures. Moreover, it ensures that the expert’s work is delivered in a dynamic fashion; let’s face it, the majority of the most exceptional professionals get bored working in the same environment all the time. Hiring a freelancer to deliver a specific framework allows the business to capitalise of their skills at their most dynamic and creative.
Finally, it’s all about rolling out proven use cases. Experts that have done it before and can share their experience from multiple industries or business areas are the best resource for rapid learning and maximum impact. The combination of experienced freelancers and a business’s own team is extremely effective when it comes to ramping up knowledge and capabilities within the organisation, while managing talent and cost effectively.
Stay ahead of the curve with data engineering
We hope this guide lays out the benefits of acquiring new practices, the full potential of automation and the need to incorporate skilled data talent into a team – no matter the size of the organisation. Moreover, it should help you see firsthand the advantages of applying techniques aligned with the ever-shifting data landscape. In summary, the following skills are vital in a data engineer, or for that matter, anyone working in the digital field:
- Parameterization.
- Scripting language.
- Organisation.
- Creativity.
- Debugging/problem solving.
- ETL Tools/software.
- Cloud data engineering skills: AWS, GCP, Azure, IBM (2+).
- Other key skills: Hive, Apache Spark, Mongodb, MySQL, PostgreSQL.
Expanding on the listed skills here, companies should look for professionals that have experience managing, processing, and handling data at various levels of complexity and at various stages. Companies should seek to hire data engineers with generalist skills who still have a lean approach to data engineering.
This does and will always prove to be rewarding in the fast-changing digital world we are living in. Generally speaking, businesses should look for what is known as the ‘four Vs’ in big data when hiring a data engineer; versatility, velocity, variety, and veracity. In regard to both structured and unstructured data, data engineers with these qualities will enjoy exploring, tinkering, and as a result, build innovative solutions.
Outvise’s talent pool
A good data engineer will love to wrangle and process data. It’s often said that processing data takes up to 50% of a data specialist’s time, not to mention a data engineer. A good data engineer will have experience and/or willingness to learn the best practices and architecture of real-time, batch processing systems. They’ll be exceptionally interested in knowing how distributed services/systems work and be insightful, research-driven, curious with a hands-on mentality. After all, it’s better to ask one more time than not enough.
So where can you find exceptional digital talent like this? How do you identify professionals that can deliver? To respond to this need, Outvise created their pool of curated digital talent. In our extensive catalogue of professionals, you can find certified data engineers, specialists and consultants that can guide and execute high-level automation projects. With these professionals and many more, head hunted by our dedicated team, you can build the perfect team for your specific project or field. Explore the portfolio of exceptional digital, tech and business talent here.


Francisco is an Expert in Data Engineering and an AI enthusiast with a hands-on approach in project development. Skilled in Problem Solving, Software Engineering, Development, Computer Vision, NLP, Python, C++, Web Development. He has a large experience as a Freelance Data Expert with different companies.



No comments yet
There are no comments on this post yet.